파이썬 리스트의 기본 개념부터 추가, 삭제, 인덱스, 반복문 활용

파이썬 리스트의 기본 개념부터 추가, 삭제, 인덱스, 반복문 활용까지 단계별로 쉽게 정리했습니다.
파이썬을 배우기 시작하면 가장 먼저 자주 만나게 되는 자료형이 바로 리스트(List)입니다.
리스트는 여러 개의 값을 하나로 묶어서 관리할 수 있게 해주는 아주 중요한 도구입니다.
예를 들어, 학생 5명의 이름을 각각 변수로 만들면 이렇게 됩니다.
name2 = "지영"
name3 = "현우"
이렇게 만들면 관리가 복잡해집니다. 하지만 리스트를 사용하면 단 한 줄로 정리할 수 있습니다.
names = ["민수", "지영", "현우", "지현", "현정"]
이게 바로 리스트의 힘입니다.
이번 글에서는 아래와 같은 내용을 정리해보려고 합니다.
- 리스트 만드는 방법
- 값 추가하기
- 값 삭제하기
- 인덱스 이해하기
- 반복문과 함께 사용하기
리스트의 개념과 기본 문법
리스트란 무엇인가?
리스트는 여러 개의 값을 한 줄로 묶는 자료형입니다. 대괄호 [] 안에 값을 넣어서 만듭니다.
numbers = [1, 2, 3, 4]
여기서 중요한 특징이 있습니다.
- 순서가 있습니다.
- 값 변경이 가능합니다.
- 서로 다른 자료형을 함께 넣을 수 있습니다.
data = [1, "hello", 3.14]처럼 숫자, 문자, 소수도 함께 넣을 수 있습니다.
인덱스 이해하기
리스트는 0번 부터 시작합니다.
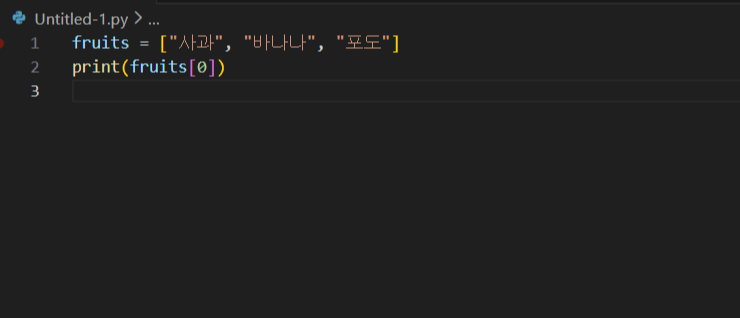
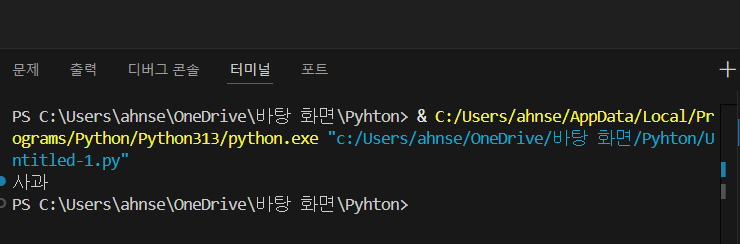
fruits = ["사과", "바나나", "포도"]
print(fruits [0]) 이렇게 값을 넣고 실행시키면 나오는 값은 뭘까요?
사과입니다.
| 위치 | 값 |
| 0 | 사과 |
| 1 | 바나나 |
| 2 | 포도 |
슬라이싱
리스트 일부만 가져오는 기능입니다.
numbers = [10, 20, 30, 40, 50]
print(numbers [1:4]) 이렇게 하면 어떤 결과 값이 나올까요?
[20, 30, 40]
시작 번호는 포함, 끝 번호는 포함되지 않습니다.


값 추가하기
append()와 insert()를 사용해 보겠습니다.
먼저 append를 사용해 보겠습니다.
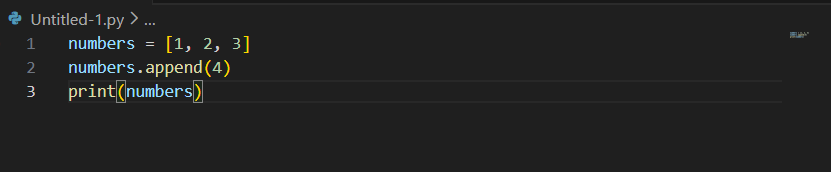
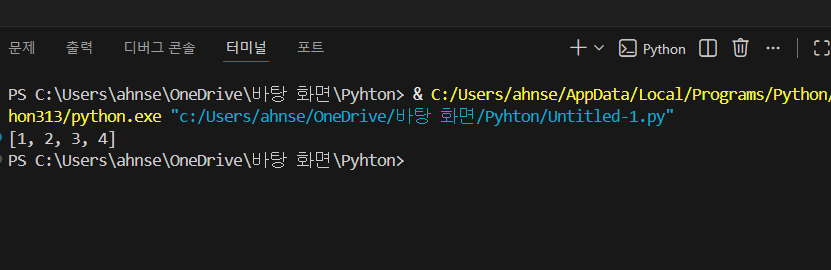
numbers = [1, 2, 3]
numbers.append(4)
append를 사용하면 항상 맨 뒤에 값이 추가되며 출력을 하면 [1, 2, 3, 4]로 나오게 됩니다.
그럼 다음으로 insert를 사용해 보겠습니다.
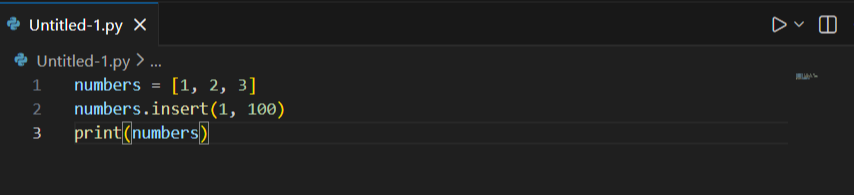
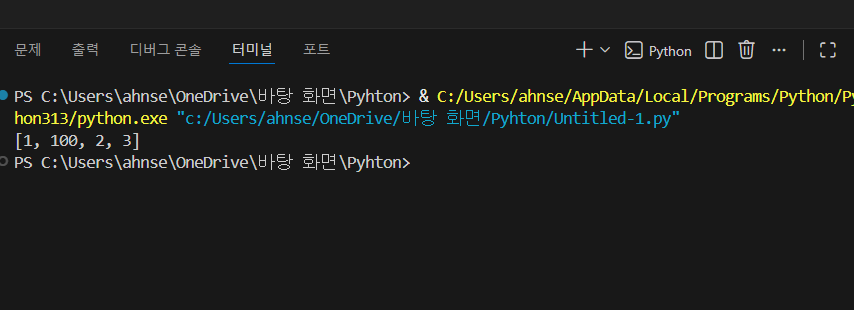
numbers = [1, 2, 3]
numbers.insert(1, 100)
이렇게 하면 1번 자리에 100을 끼워 넣고 나머지 값은 뒤로 밀리게 됩니다.
그래서 1, 100, 2, 3으로 값이 출력됩니다.
값 삭제하기
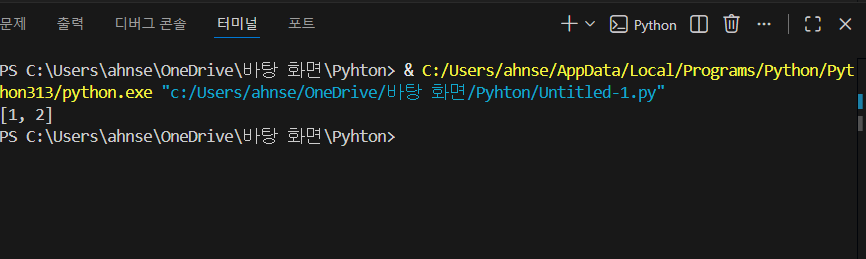
그럼 remove()와 pop()을 사용해 보겠습니다.
numbers.remove(2)
출력된 값을 보면 [1, 3]만 있습니다. 이건 remove를 이용해서 2번을 삭제했기 때문에 1과 3만 출력된 것을 확인할 수 있습니다.


pop()의 기능은 가장 마지막에 있는 값을 삭제합니다.

길이 확인하기 및 정렬하기
리스트 안에 몇 개가 들어있는지 확인합니다.
len(numbers)
numbers.sort() 오름 차순으로 정리할 때 사용합니다.
점수 평균 구하기
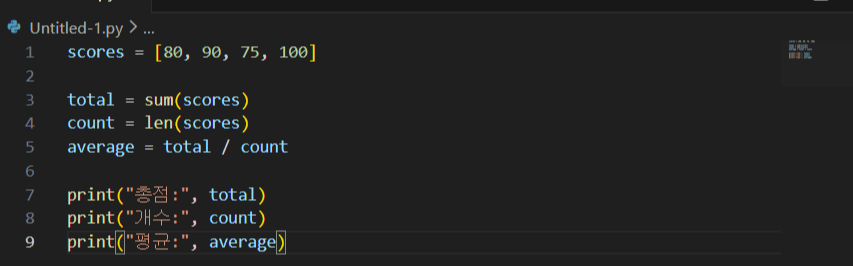

- 리스트에는 “여러 점수”가 들어가므로 scores 하나로 묶어 관리합니다.
- sum(scores)는 리스트의 합계를 한 번에 구하니 반복문보다 짧고 실수가 줄어듭니다.
- 평균은 “합계 ÷ 개수”이므로 len(scores)로 개수를 구합니다.
- 중간 값(total, count)을 변수로 분리하면 디버깅(확인)이 쉬워집니다.
장바구니 목록 만들기 (추가/출력)


- 장바구니는 “계속 물건이 늘어나는 구조”라서 리스트가 딱 맞습니다.
- cart = []로 빈 리스트를 만들고, append()로 뒤에 쌓아 올립니다.
- append()는 “맨 뒤에 추가”라서 사용 패턴이 단순하고 직관적입니다.
특정 값 삭제하기 (remove)

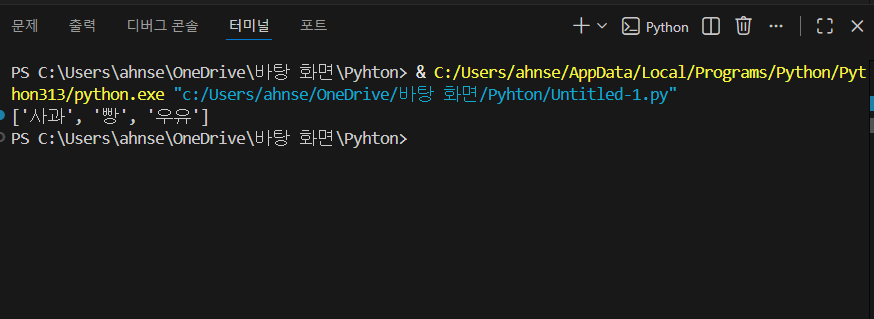
- remove("우유")는 리스트에서 해당 값(문자열)을 찾아 삭제합니다.
- 중요한 포인트: remove()는 같은 값이 여러 개면 첫 번째 것만 지웁니다.
- 그래서 “중복된 값 관리”가 필요한 상황에서는 반복문/조건이 추가로 필요합니다(뒤 예제에서 다룹니다).
마지막 항목 꺼내기 (pop) + 꺼낸 값 사용


- pop()은 “삭제하면서 동시에 그 값을 돌려주는” 함수입니다.
- 그래서 last_task = tasks.pop()처럼 꺼낸 값을 바로 변수에 담아 활용할 수 있습니다.
- “스택(쌓아 올리는 구조)”처럼 마지막부터 처리할 때 자연스럽습니다.
최댓값/최솟값 찾기 (max/min)
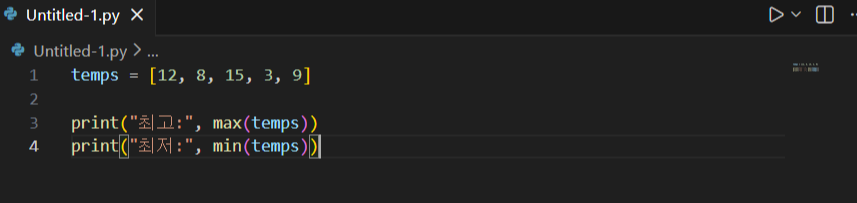

- 최댓값/최솟값은 반복문으로도 찾을 수 있지만 max(), min()이 가장 안전하고 짧습니다.
- 코드 길이가 짧아질수록 “조건 실수(>, >=)” 같은 오류 가능성이 줄어듭니다.
짝수만 골라 새 리스트 만들기 (필터링)
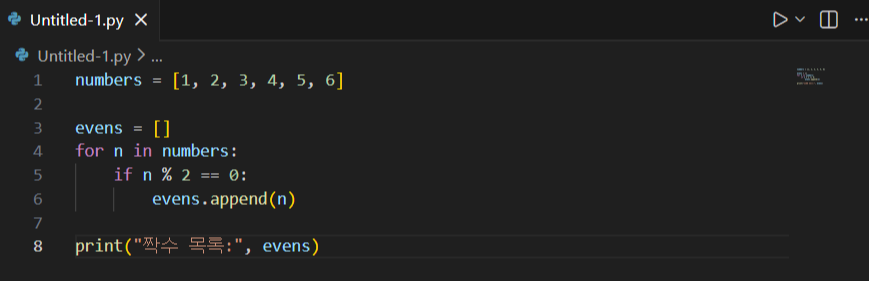

- “조건에 맞는 것만 모으기”는 실무에서 가장 흔한 패턴이라 기본 반복문 방식이 중요합니다.
- evens = []를 따로 만드는 이유는 원본 데이터를 건드리지 않고 결과만 새로 만들기 위해서입니다.
- n % 2 == 0은 “2로 나눴을 때 나머지가 0이면 짝수”라는 가장 표준적인 규칙입니다.
중복 제거하기 (순서 유지 버전)
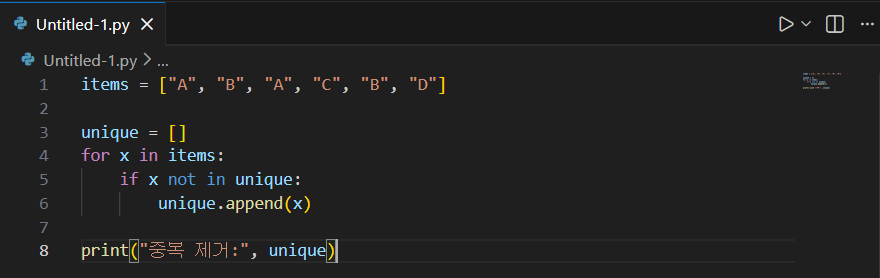

- set(items)로도 중복 제거가 되지만, set은 순서가 깨질 수 있습니다.
- 여기서는 “처음 나온 순서를 그대로 유지”하는 방법을 사용했습니다.
- if x not in unique:는 이미 들어간 값인지 검사하고, 없을 때만 추가합니다.
- 리스트가 매우 커지면 not in 검사 비용이 커질 수 있는데, 기본 원리를 이해하는 게 먼저입니다.
정렬 + 내림차순 만들기 (sort vs sorted)
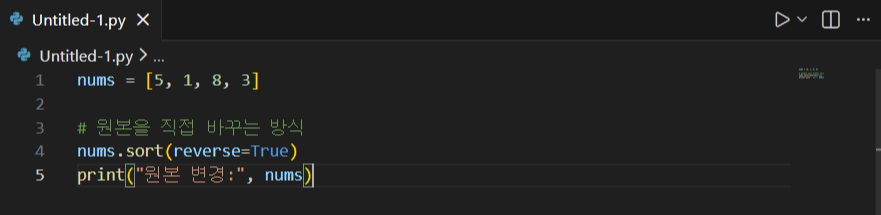
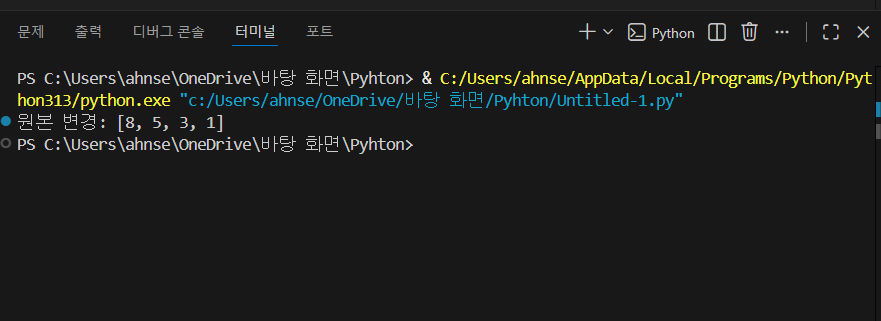
- sort()는 리스트 자체를 바꿉니다(원본 변경).
- reverse=True를 주면 내림차순이 됩니다.
- “원본을 유지해야 하는 상황”이면 sorted(nums, reverse=True)를 쓰는 게 더 안전합니다.
- 즉, sort()는 빠르고 간단하지만 원본이 바뀐다는 점을 알고 써야 합니다.
가장 많이 나온 값 찾기 (빈도 카운트: 리스트만 사용)

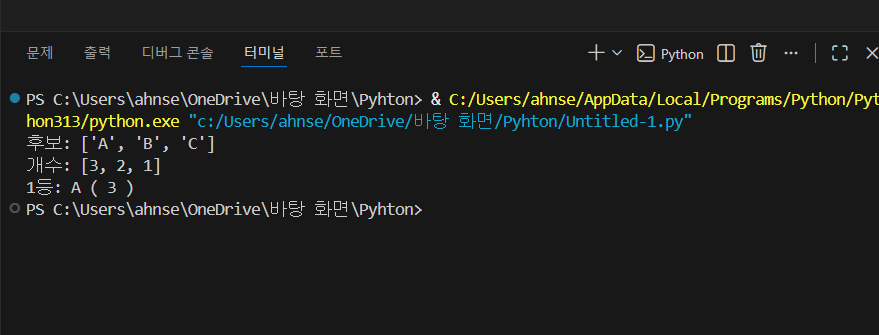
- 딕셔너리를 쓰면 더 짧아지지만, 여기서는 리스트만으로 빈도 계산 원리를 보여주기 위해 이렇게 구성했습니다.
- unique는 “등장한 후보 목록”, counts는 “각 후보의 등장 횟수”입니다.
- 같은 인덱스를 공유하게 만들어서 unique [i]의 개수는 counts [i]로 연결됩니다.
- index()를 쓰는 이유는 “그 값이 unique의 몇 번째 칸인지” 찾아야 counts를 올릴 수 있기 때문입니다.
- 마지막에 max_count와 winner_index를 분리한 이유는 과정이 명확해지고 디버깅이 쉬워집니다.
간단한 체크리스트 프로그램 (추가/완료/출력)
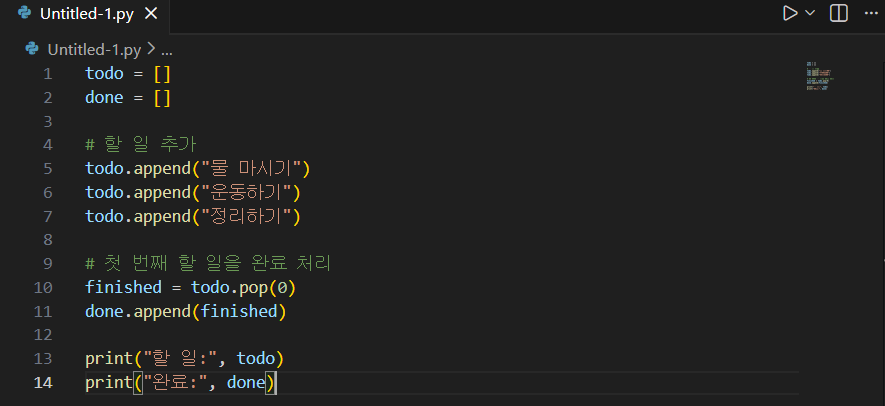
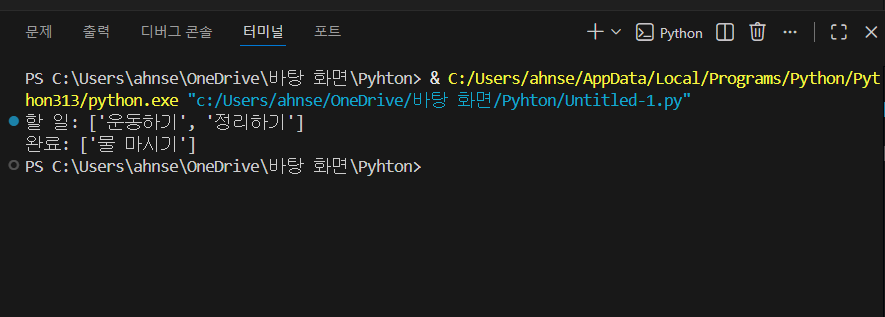
- todo와 done을 분리하면 “해야 할 것”과 “끝난 것”이 섞이지 않아 관리가 편합니다.
- pop(0)은 맨 앞 요소를 꺼내는 방식입니다. 즉, “먼저 들어온 일을 먼저 처리”하는 흐름(FIFO)을 만들 수 있습니다.
- 꺼낸 값을 finished에 담는 이유는, 그 값을 바로 done.append()에 넘겨 “완료 목록”으로 옮기기 위해서입니다.
- 이 패턴은 작업 큐, 대기열 같은 구조의 가장 기초가 됩니다.
- 리스트(List)는 왜 쓰나요? 그냥 변수 여러 개 쓰면 안 되나요?
- 리스트는 여러 값을 한 덩어리로 묶어서 한 번에 관리할 때 가장 효율적입니다.
- 먼저 변수 여러 개를 쓰면 이름을 계속 늘려야 해서 관리가 금방 어려워집니다.
- 다음으로 리스트는 반복문과 합이 좋아서 같은 작업을 여러 값에 자동으로 적용할 수 있습니다.
- 사용 절차는 []로 리스트를 만들고, 값을 넣고, 인덱스로 꺼내는 흐름을 잡으면 됩니다.
- 예를 들어 scores = [80, 90, 75]처럼 만들면 점수 목록을 한 번에 저장할 수 있습니다.
- 주의할 점은 리스트 안 값은 순서가 있고, 그 순서가 의미를 가질 수 있다는 점입니다.
- 또한 값이 추가/삭제되면 인덱스 번호가 바뀌므로 “번호로 접근하는 코드”는 영향이 생길 수 있습니다.
- 그래서 “항목이 자주 바뀌는 리스트”는 인덱스를 직접 고정해 쓰는 방식보다 검색/조건을 섞는 편이 안전합니다.
- 확장 팁으로, 리스트는 데이터 처리의 기본이라 이후 딕셔너리/튜플/셋과 함께 쓰면 구조 설계가 훨씬 쉬워집니다. 정리하면 리스트는 “많은 값을 한 번에 다루기 위한 기본 도구”입니다.
- 리스트 인덱스가 0부터 시작하는 이유가 있나요?
- 파이썬 리스트는 첫 번째 칸의 위치를 0으로 두는 규칙을 사용합니다.
- 핵심은 “첫 칸에서 얼마나 떨어졌는가”라는 거리 개념으로 접근하기 편하기 때문입니다.
- 사용 절차는 리스트를 만들고 list [0]이 첫 값이라는 규칙을 먼저 몸에 익히는 것입니다.
- 예를 들어 fruits = ["사과", "바나나", "포도"] 면 fruits [0]은 사과입니다.
- 이 규칙 덕분에 슬라이싱에서 a:b처럼 “b는 포함하지 않는다” 규칙도 깔끔하게 맞물립니다.
- 주의할 점은 길이가 3인 리스트에서 마지막 인덱스는 2라는 점입니다. 그래서 fruits [3]처럼 존재하지 않는 칸을 부르면 IndexError가 발생합니다.
- 안전하게 접근하려면 먼저 len(fruits)로 길이를 확인하는 습관이 좋습니다.
- 확장 팁으로, 파이썬은 음수 인덱스를 지원해서 fruits [-1]은 마지막 값을 의미합니다. 정리하면 0부터 시작은 불편해 보이지만 반복/슬라이싱/거리 계산에서 매우 강력합니다.
- 음수 인덱스(-1)는 언제 쓰면 좋은가요?
- 음수 인덱스는 “뒤에서부터 빠르게 접근”할 때 가장 편합니다. 핵심은 -1이 마지막, -2가 끝에서 두 번째라는 규칙입니다.
- 절차는 리스트가 있을 때 뒤쪽 값이 필요한 상황에서 list [-1]을 먼저 떠올리면 됩니다. 예를 들어 nums = [10, 20, 30]이면 nums [-1]은 30입니다.
- 이 방식은 “길이가 변해도 마지막 값”을 안정적으로 꺼낼 수 있다는 장점이 있습니다.
- 주의할 점은 빈 리스트에서 [-1]로 접근하면 당연히 오류가 납니다. 그래서 비어 있을 가능성이 있으면 if len(nums) > 0: 같은 체크를 먼저 하는 게 안전합니다. 또는 “마지막 값 제거 + 반환”이 목적이면 pop()이 더 알맞을 때가 많습니다.
- 확장 팁으로, 슬라이싱에서도 음수를 쓰면 nums [:-1]처럼 마지막 하나를 제외하고 가져오는 표현이 가능합니다.
- 정리하면 음수 인덱스는 “끝에서부터” 다룰 때 가장 빠르고 깔끔한 방법입니다.
- 슬라이싱 a:b에서 b가 포함되지 않는 이유가 뭔가요?
- 슬라이싱에서 끝 인덱스를 포함하지 않는 규칙은 범위를 계산하기 쉽게 만들기 위한 선택입니다. 핵심은 “몇 개를 뽑았는지”가 b-a로 바로 계산된다는 점입니다.
- 사용 절차는 list [a:b]는 a부터 b 직전 까지라는 규칙을 고정해 기억하는 것입니다. 예를 들어 nums = [0,1,2,3,4]에서 nums [1:4]는 [1,2,3]입니다.
- 이 규칙 때문에 nums [:3]은 처음부터 3개, nums [3:]은 3번부터 끝까지가 됩니다. 주의할 점은 슬라이싱은 “원본을 바꾸지 않고 새 리스트를 만든다”는 점입니다.
- 그래서 큰 리스트를 자주 슬라이싱하면 메모리 사용이 늘어날 수 있습니다. 필요할 때만 슬라이싱 하고, 반복 처리로 해결할 수 있으면 반복이 더 효율적일 때도 있습니다.
- 확장 팁으로 세 번째 값(스텝)을 넣어 nums [::2]처럼 2칸씩 건너뛰는 선택도 가능합니다. 정리하면 끝이 포함되지 않는 규칙은 계산과 조합에 유리한 “설계 규칙”입니다.
- append()와 insert()는 어떤 차이가 있나요?
- append()는 맨 뒤에 추가하고, insert()는 원하는 위치에 끼워 넣습니다. 핵심은 “추가 위치를 지정하느냐”입니다.
- 절차는 뒤에 쌓을 때는 append(value), 특정 위치가 중요하면 insert(index, value)를 씁니다. 예를 들어 a = [1,2]에서 a.append(3)은 [1,2,3]이 됩니다.
- 반면 a.insert(0, 9)는 [9,1,2,3]처럼 맨 앞에 넣을 수 있습니다. 주의할 점은 insert()는 앞이나 중간에 넣으면 뒤쪽 요소들이 밀리면서 리스트가 재배치됩니다.
- 그래서 요소가 매우 많을 때는 insert()가 자주 쓰이면 성능이 느려질 수 있습니다. 반면 append()는 뒤에 붙이기라 상대적으로 부담이 적고 가장 흔히 씁니다.
- 확장 팁으로, “여러 개를 한 번에 뒤에 붙이기”는 extend()를 사용하면 깔끔합니다. 정리하면 규칙은 간단합니다: 뒤면 append, 자리 지정이면 insert입니다.
- remove()와 pop()은 어떻게 다르고, 어떤 걸 써야 하나요?
- remove()는 “값을 찾아서 삭제”, pop()은 “인덱스로 꺼내면서 삭제”입니다. 핵심은 삭제 기준이 “값이냐, 위치(인덱스)냐”입니다.
- 절차는 특정 값 하나를 지우려면 remove(value)를 쓰고, 특정 칸을 꺼내려면 pop(index)를 씁니다. 예를 들어 a=[1,2,3]에서 a.remove(2)는 [1,3]이 됩니다.
- a.pop()은 마지막을 꺼내며 3을 반환하고 리스트는 [1,2]로 바뀝니다. 주의할 점은 remove()는 같은 값이 여러 개면 “첫 번째만” 지웁니다.
- 또한 존재하지 않는 값을 remove()하면 ValueError가 납니다. pop()도 없는 인덱스를 주면 IndexError가 나니 길이 확인이 필요합니다.
- 확장 팁으로, 삭제 후 그 값을 계속 써야 하는 흐름이면 pop()이 더 자연스럽습니다. 정리하면 값 기준 삭제는 remove, 꺼내면서 삭제는 pop입니다.
- 리스트 길이는 왜 len()으로 구하나요? count()랑 헷갈려요.
- len()은 “총 개수”, count()는 “특정 값이 몇 개 있는지”를 셉니다. 핵심은 대상이 “리스트 전체”냐 “리스트 안 특정 값”이냐입니다.
- 절차는 리스트 칸 수가 필요하면 len(list)를 먼저 쓰면 됩니다. 예를 들어 a=[1,1,2]에서 len(a)는 3입니다.
- 반면 a.count(1)은 값 1이 몇 개인지라 결과는 2입니다.
- 주의할 점은 count()는 리스트 전체를 훑어서 세기 때문에 큰 리스트에서 자주 호출하면 부담이 커질 수 있습니다.
- 또한 len()은 거의 모든 시퀀스(문자열 등)에서도 똑같이 쓰이므로 기본기가 됩니다.
- 확장 팁으로, “길이 기반 반복”이 필요하면 range(len(a)) 패턴도 자주 쓰지만, 보통은 for x in a가 더 안전합니다. 정리하면 len()은 전체 칸 수, count()는 값의 개수입니다.
- 리스트에서 값이 있는지 빠르게 확인하는 방법이 있나요?
- 가장 기본은 in 연산자를 쓰는 것입니다. 핵심은 value in list가 True/False를 즉시 알려준다는 점입니다.
- 절차는 조건문에서 if "우유" in cart:처럼 검사하는 습관을 들이면 됩니다. 예를 들어 cart=["사과", "우유"]에서 "우유" in cart는 True입니다.
- 이 방식은 읽기 쉬워서 코드의 의도가 바로 보입니다. 주의할 점은 리스트는 내부를 순서대로 찾기 때문에 항목이 엄청 많으면 느려질 수 있습니다.
- 그럴 때는 “검사용 자료구조”를 셋(set)으로 바꾸는 전략도 있습니다. 하지만 리스트 기본 단계에서는 우선 in으로 정확히 쓰는 것이 가장 중요합니다.
- 확장 팁으로, 존재 여부만 필요하면 index()를 바로 쓰지 말고 in으로 먼저 검사하면 오류를 줄일 수 있습니다.
- 정리하면 리스트 포함 여부는 in이 가장 표준입니다.
- index()는 언제 쓰고, 왜 위험하다고 하나요?
- index()는 특정 값이 “처음 등장하는 위치(인덱스)”를 찾는 함수입니다. 핵심은 값이 없으면 에러가 난다는 점입니다.
- 절차는 if value in list:로 존재 확인 후 list.index(value)를 호출하는 방식이 안전합니다. 예를 들어 a=["A", "B", "C"]에서 a.index("B")는 1입니다.
- 하지만 a.index("Z")는 값이 없으니 ValueError가 납니다. 주의할 점은 중복 값이 있으면 “첫 번째 위치만” 반환하므로 모든 위치가 필요하면 반복문이 필요합니다.
- 또한 index()도 내부 탐색이 들어가므로 큰 리스트에서 반복 호출하면 부담이 커집니다.
- 확장 팁으로, 위치가 중요하면 데이터 구조를 “값→위치” 형태로 바꾸는 전략(딕셔너리)을 고려할 수 있습니다.
- 정리하면 index()는 편하지만 “없을 때 에러”와 “중복 처리”를 반드시 의식해야 합니다.
- 리스트 정렬은 sort()랑 sorted() 중 뭐가 더 좋나요?
- 둘 다 정렬이지만, sort()는 원본을 바꾸고 sorted()는 새 리스트를 만듭니다. 핵심은 “원본 보존 여부”입니다.
- 절차는 원본을 바꿔도 되면 a.sort(), 원본을 유지해야 하면 b = sorted(a)를 씁니다. 예를 들어 a=[3,1,2]에서 a.sort() 후 a는 [1,2,3]이 됩니다. 반면 sorted(a)는 정렬된 결과를 반환하지만 a 자체는 그대로일 수 있습니다.
- 주의할 점은 정렬 후 원본이 바뀐 걸 모르고 뒤에서 원본 순서를 기대하면 버그가 생깁니다. 그래서 “정렬 전/후를 비교”하거나 “원본 순서를 유지해야 하는 로직”이면 sorted가 안전합니다.
- 확장 팁으로, 내림차순은 reverse=True 옵션으로 통일하면 됩니다. 정리하면 빠르게 바꾸면 sort, 안전하게 보존하면 sorted입니다.
- 리스트를 반복문으로 도는 기본 형태는 뭐가 가장 좋은가요?
- 가장 기본은 for item in list: 형태입니다. 핵심은 인덱스보다 “값 자체”로 반복하는 것이 오류가 적다는 점입니다.
- 절차는 리스트를 만들고 for x in a:로 하나씩 꺼내 처리하면 됩니다. 예를 들어 for n in [1,2,3]: print(n)처럼 쓰면 1,2,3이 순서대로 출력됩니다.
- 주의할 점은 반복 중에 리스트를 직접 삭제/추가하면 예상치 못한 결과가 나올 수 있습니다.
- 특히 for로 돌면서 remove()를 하면 건너뛰는 항목이 생길 수 있습니다. 이럴 때는 “새 리스트에 담기” 전략(필터링)으로 해결하는 편이 안전합니다.
- 확장 팁으로 인덱스도 필요하면 enumerate(a)를 사용하면 (인덱스, 값)을 동시에 받을 수 있습니다. 정리하면 기본은 for 값 in 리스트, 인덱스 필요시 enumerate입니다.
- enumerate()는 왜 쓰나요? 그냥 range(len()) 쓰면 되지 않나요?
- enumerate()는 인덱스와 값을 동시에 제공해 코드가 깔끔해집니다. 핵심은 range(len(a))보다 읽기 쉽고 실수(인덱스 오타)가 줄어든다는 점입니다.
- 절차는 for i, x in enumerate(a): 형태를 기본으로 익히면 됩니다. 예를 들어 a=["사과", "바나나"] 면 i는 0,1이고 x는 각 과일이 됩니다.
- 이 방식은 “몇 번째인지”와 “무슨 값인지”를 함께 처리할 때 아주 자주 씁니다.
- 주의할 점은 enumerate도 결국 인덱스를 주지만, 인덱스로 원본을 수정하는 로직은 여전히 조심해야 합니다. 또한 시작 값을 1로 하고 싶다면 enumerate(a, start=1)을 쓰면 됩니다.
- 확장 팁으로, 출력이나 로그를 찍을 때 “번호 매기기”에 특히 좋습니다. 정리하면 enumerate는 반복문에서 인덱스가 필요한 가장 표준적인 방법입니다.
- 리스트를 복사했는데 원본이 같이 바뀌어요. 왜 그런가요?
- b = a는 복사가 아니라 “같은 리스트를 가리키는 연결”입니다. 핵심은 a와 b가 동일한 객체를 공유하는 상태가 된다는 점입니다. 절차는 진짜 복사가 필요하면 a.copy() 또는 a [:]를 사용합니다.
- 예를 들어 a=[1,2]에서 b=a 후 b.append(3)을 하면 a도 [1,2,3]이 됩니다. 반면 b=a.copy()로 만들면 b만 바뀌고 a는 그대로일 수 있습니다.
- 주의할 점은 리스트 안에 리스트가 있는 “중첩 리스트”는 얕은 복사로는 부족할 수 있습니다.
- 중첩 구조에서는 내부 리스트가 공유되어 예상치 못한 동시 변경이 생길 수 있습니다. 그럴 때는 copy 모듈의 deepcopy 개념이 필요하지만, 기본 단계에서는 “얕은 복사”부터 확실히 잡는 게 좋습니다.
- 확장 팁으로, 디버깅할 때 id(a)와 id(b)를 출력하면 같은 객체인지 확인할 수 있습니다. 정리하면 =는 연결, copy()는 복사입니다.
- 리스트 안에 리스트(2차원 리스트)는 어떻게 다루나요?
- 2차원 리스트는 “리스트의 각 칸에 또 리스트가 들어있는 구조”입니다. 핵심은 a [row][col]처럼 두 번 인덱싱 한다는 점입니다.
- 절차는 먼저 전체 형태를 만들고, 바깥 인덱스로 행을 고른 뒤, 안쪽 인덱스로 열을 고릅니다.
- 예를 들어 grid = [[1,2,3], [4,5,6]]에서 grid [0]은 [1,2,3]입니다. 그리고 grid[0][1]은 2가 됩니다.
- 주의할 점은 행 길이가 서로 다른 “들쭉날쭉 리스트”도 만들 수 있어 인덱스 오류가 나기 쉽습니다.
- 그래서 표 형태처럼 쓰려면 각 행의 길이를 동일하게 유지하는 습관이 좋습니다. 확장 팁으로, 2차원 리스트는 중첩 반복문으로 순회하는 패턴이 기본입니다.
- 정리하면 2차원 리스트는 “바깥→안쪽” 순서로 접근합니다.
- 리스트에서 여러 값을 한 번에 추가하는 가장 좋은 방법은 뭔가요?
- 여러 값을 추가할 때는 extend()가 깔끔합니다. 핵심은 append()는 하나만, extend()는 여러 개를 펼쳐서 붙인다는 점입니다.
- 절차는 기존 리스트에 다른 리스트를 합칠 때 a.extend(b)를 사용하면 됩니다. 예를 들어 a=[1,2], b=[3,4]면 a.extend(b) 후 a는 [1,2,3,4]가 됩니다.
- 반면 a.append(b)를 하면 [1,2,[3,4]]처럼 “리스트가 통째로 한 칸” 들어가 버립니다. 주의할 점은 append()와 extend() 혼동이 실제로 매우 흔한 실수입니다.
- 그래서 “결과가 중첩 리스트가 되었는지” 출력해서 확인하는 습관이 좋습니다.
- 확장 팁으로, a + b도 가능하지만 새 리스트를 만들기 때문에 메모리 관점에서 다를 수 있습니다. 정리하면 여러 개를 붙이면 extend, 하나(값)를 붙이면 append입니다.
- 리스트에서 특정 조건에 맞는 값만 골라 새 리스트를 만드는 방법은?
- 가장 안전한 방법은 “빈 리스트를 만들고 조건에 맞으면 append”하는 방식입니다. 핵심은 반복 중 원본을 직접 수정하지 않는 것입니다.
- 절차는 result=[] 만들고 for로 돌면서 if 조건:일 때 result.append() 합니다. 예를 들어 짝수만 모으려면 if n % 2 == 0: 조건을 씁니다.
- 이 방식은 로직이 명확해서 오류가 나도 어디서 틀렸는지 바로 찾기 쉽습니다.
- 주의할 점은 조건이 복잡해질수록 괄호/우선순위 실수가 생길 수 있으니 조건을 변수로 분리하면 좋습니다.
- 또한 결과를 만들 때 원본 순서를 그대로 유지한다는 장점이 있습니다. 확장 팁으로, 같은 작업은 리스트 컴프리헨션으로도 만들 수 있지만, 기본은 반복문 방식이 더 읽기 쉽습니다.
- 정리하면 “새 리스트 만들기” 패턴이 필터링의 정석입니다.
- 리스트 컴프리헨션은 왜 쓰고, 언제 쓰면 위험한가요?
- 리스트 컴프리헨션은 “필터링/변환”을 한 줄로 만드는 문법입니다. 핵심은 코드를 짧게 하지만, 너무 복잡해지면 읽기 어려워진다는 점입니다.
- 절차는 단순 변환부터 시작합니다. 예: squares = [x*x for x in nums] 형태입니다. 예를 들어 nums=[1,2,3]이면 결과는 [1,4,9]가 됩니다.
- 조건을 붙이면 evens = [x for x in nums if x % 2 == 0]처럼 작성합니다. 주의할 점은 if가 여러 개이거나 삼항 연산이 섞이면 가독성이 급격히 떨어집니다.
- 가독성이 떨어지면 나중에 수정할 때 실수가 늘어납니다. 확장 팁으로 “한 줄이 너무 길다” 싶으면 즉시 기본 반복문으로 바꾸는 게 유지보수에 유리합니다.
- 정리하면 짧고 단순할 때는 강력하지만, 복잡해지면 반복문이 더 안전합니다.
- 리스트를 문자열로 합치거나, 문자열을 리스트로 나누는 방법은?
- 문자열 합치기는 join(), 문자열 나누기는 split()이 기본입니다. 핵심은 join은 “리스트 → 문자열”, split은 “문자열 → 리스트”입니다.
- 절차는 먼저 리스트가 문자열 리스트인지 확인하고, 구분자와 함께 join을 씁니다. 예를 들어 words=["안녕","하세요"]면 " ".join(words)는 "안녕 하세요"가 됩니다. 반대로 "a,b,c".split(",")는 ["a","b","c"]가 됩니다.
- 주의할 점은 join은 리스트에 숫자가 섞이면 오류가 나므로 반드시 문자열로 바꿔야 합니다.
- 또한 split은 구분자가 연속될 때 빈 문자열이 끼어들 수 있어 결과를 출력해 확인하는 습관이 좋습니다.
- 확장 팁으로, 파일 처리나 CSV 같은 텍스트 데이터에서 이 패턴이 매우 자주 등장합니다. 정리하면 join과 split은 방향만 헷갈리지 않으면 됩니다.
- 리스트에서 “모든 항목 삭제”와 “리스트 자체 초기화”는 어떻게 달라요?
- 모든 항목 삭제는 clear()로 리스트를 비우는 것입니다. 핵심은 변수 자체는 유지하되, 내용만 비운다는 점입니다.
- 절차는 a.clear()를 호출하면 리스트가 []가 됩니다. 예를 들어 a=[1,2,3]에서 a.clear() 후 a는 빈 리스트입니다.
- 반면 a = []로 새 리스트를 할당하면 “새 객체”가 됩니다.
- 주의할 점은 다른 변수도 같은 리스트를 가리키고 있던 상황에서는 clear()가 영향을 줄 수 있습니다. 즉, 공유된 리스트면 모두 비워지는 효과가 생길 수 있습니다.
- 확장 팁으로, 코드가 여러 곳에서 참조하는 리스트라면 “비우기”인지 “새로 만들기”인지 의도를 분명히 하는 게 좋습니다.
- 정리하면 clear는 내용만 비우기, =[]는 새로 만들기입니다.
- 리스트를 다룰 때 가장 자주 나는 에러 3가지와 해결법은?
- 리스트 에러는 대부분 인덱스/값/복사에서 발생합니다. 핵심은 IndexError, ValueError, “얕은 복사 문제” 3가지를 먼저 잡는 것입니다.
- 절차는 첫째, 인덱스 접근 전 len()으로 범위를 확인하는 습관을 들입니다. 둘째, remove()나 index()를 쓰기 전에는 in으로 존재 여부를 검사합니다.
- 셋째, 복사할 때는 b=a가 복사가 아니라는 점을 기억하고 copy()를 사용합니다. 예를 들어 마지막 값을 꺼낼 때 빈 리스트면 pop()이 실패하니 비어 있는지 먼저 체크해야 합니다.
- 또한 중복 값이 있을 때 remove()는 첫 번째만 지우니 “모두 삭제”가 필요하면 다른 전략이 필요합니다.
- 확장 팁으로, 리스트를 다루는 코드는 중간중간 print()로 상태를 찍어 확인하면 실수가 크게 줄어듭니다. 정리하면 “길이 확인, 존재 확인, 올바른 복사” 이 3가지만 지켜도 대부분의 에러가 잡힙니다.
파이썬 리스트는 데이터를 묶어서 관리하는 가장 기본이 되는 자료형입니다.
오늘 정리한 내용만 정확하게 이해해도 다음 단계로 넘어갈 수 있습니다.
리스트 생성, 인덱스 이해, 추가/삭제, 반복문 활용, 실전 예제 적용
리스트는 모든 파이썬 프로그램의 시작점입니다.
지금 당장 직접 코드를 입력해 보면 이해가 훨씬 빨라집니다.
[Python] 파이썬 기본 연산자(+, -, , /) 완벽 정리
파이썬에서 가장 먼저 이해해야 할 기본 연산자 +, -, *, /의 개념과 동작 원리를 실제 예제로 단계별로 정리합니다. 계산 결과가 왜 그렇게 나오는지 정확히 설명합니다.
ochosblogg.blogspot.com
[Python] 파이썬 변수와 자료형 완벽 정리
파이썬 변수와 자료형의 개념과 예제까지 단계별로 정리합니다. 파이썬을 처음 배우거나 다시 정리하려고 할 때 가장 먼저 마주치는 개념이 변수와 자료형입니다.이 두 개념이 정확하게 잡히지
raphaelstory777.tistory.com
[Python] 파이썬 문자열(String) 기초 완전 정리 – 실무에서 바로 쓰는 문자열 처리 방법
파이썬 문자열(String)의 개념부터 자주 발생하는 오류, 문자열 처리 방법까지 단계별로 정리합니다. 파이...
blog.naver.com
'Python' 카테고리의 다른 글
| [Python] 파이썬 파일 읽기 쓰기 기본 정리 (0) | 2026.02.26 |
|---|---|
| [Python] 파이썬 Set 교집합·합집합·차집합 실전 활용법 (0) | 2026.02.25 |
| [Python] 파이썬 변수와 자료형 완벽 정리 (0) | 2026.02.09 |
| [Python] 파이썬 print 함수 기초 설명 (0) | 2025.11.19 |
| [Python] 파이썬 처음 시작할 때 꼭 알아야 할 IDLE 사용법! (0) | 2025.05.18 |



